
In a project or upgrading Zenoss for a large customer, I have had numerous issues regarding i/o performance. This was certainly expected, but not to that level. Some numbers to explain the situation:
- the NMS monitors about 1’900 devices
- Includes about 700+ routers and 1000+ switches
- Some switches are stacked
- On routers, we collect 8 SNMP metrics for each ethernet port
- On switches, we collect 6 SNMP metrics for each ethernet port
The total number of data-points is about 255’000, collected at 5 minute interval, constantly, never paused, always.
Doing some math : 255’000 / (5 * 60) = 850. So we do collect 850 data points per second, and these must be written to disk.
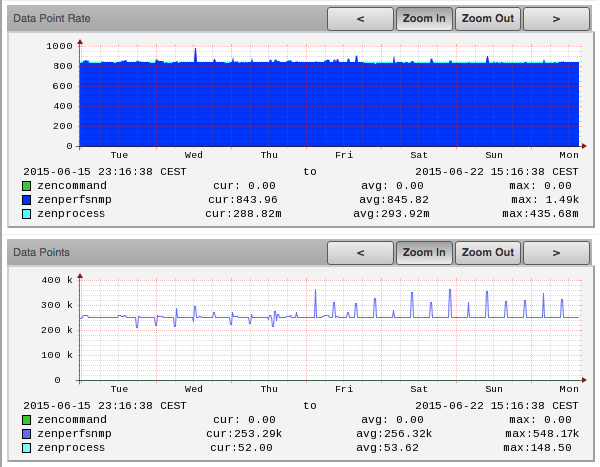
A large NMS (a Zenoss Core instance) polling 250’000+ data points every 5 minutes (~ 845 RRD-updates per second).
Might not be a high number at first sight, but think again: a normal, rotating disk has an access-time of 10-15 ms, and cannot parallelise writes. So a normal disk cannot do much more than 60-100 random writes per seconds, and this is when it is otherwise completely idle. So… we do have about 10 times more disk writes per second than what a single disk can do.
Until recently, we spread the load on multiple local disks using RAID 0 (plus RAID 1 for redundancy). But we did read the limits as well, and the NMS started to have problems writing data to the filesystems, lending to all sorts of holes in graphs, missing events, etc.
Possible approaches to mitigate the problem:
- one obvious solution would be to limit the number of collected SNMP metrics. But we did that already, e.g. by stopping QoS monitoring, which by itself added 100’000+ metrics.
- Most NMS use RRD as storage for their metrics. This is known to be a problem when load increase, because having one file for one or few metrics is not particularly smart. I think a better way would be to use something like OpenTSDB or InfluxDB, but I haven’t got the proper experience, it’s more like a feeling that it would be more efficient. The problem is, there aren’t so many products using these time-serie databases yet.
We identified as well one aggravating factor : long-running ESX snapshots where impacting the i/o performance a lot. So if you need snapshots, do not forget to delete them after a few days.
How we solved the problem: when we moved the VM storage to local SSD’s, the problems went away immediately. CPU load went down, i/o where immediate, GUI was faster, no graph holes, everything is now much better.
So the question is what storage system to buy for new servers. Do not stop at calculating the CPU and RAM galore that you will buy, but include storage performance in your calculations. Going from the best to the worst. First, what would be appropriate:
- locally-connected SSD’s (e.g. PCI-express bus)
- SSD’s over a very fast fabric, near-local
- SSD’s over fiber-channel or 10 Gb ethernet
- Mix of mechanical disks and generous SSD caches over any transport listed above
Then, continuing the list down to the worst alternatives and certainly not appropriate for anything else than the normal office server workload:
- storage over IP-SCSI over 1 Gb ethernet
- storage over NFS over TCP over IP over 1 Gb ethernet
These two solutions are so slow than using SSD or disks will probably not provide any valuable difference.
Two interesting reads about selecting your SSD’s:
- https://blog.algolia.com/when-solid-state-drives-are-not-that-solid/
- http://www.aerospike.com/docs/operations/plan/ssd/ssd_certification.html
Conclusion is, only the best performing i/o subsystems will guaranty a performing NMS platform.